Yi-Hsin Chen Wei-Yu Chen Yu-Ting Chen Bo-Cheng Tsai Yu-Chiang Frank Wang Min Sun
[Dataset]
[Our Method]
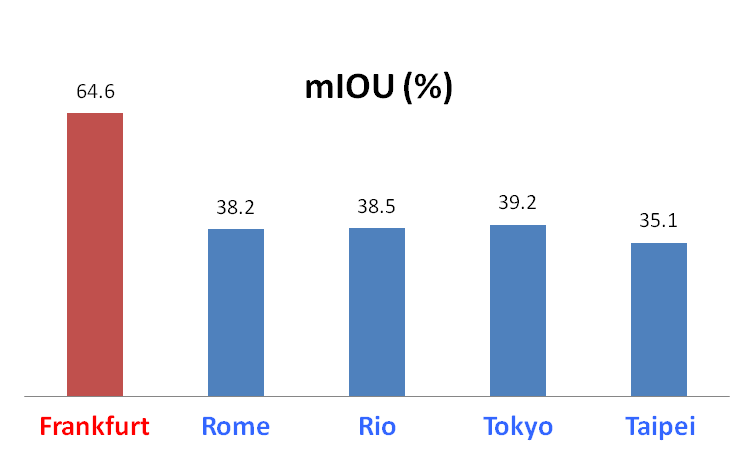
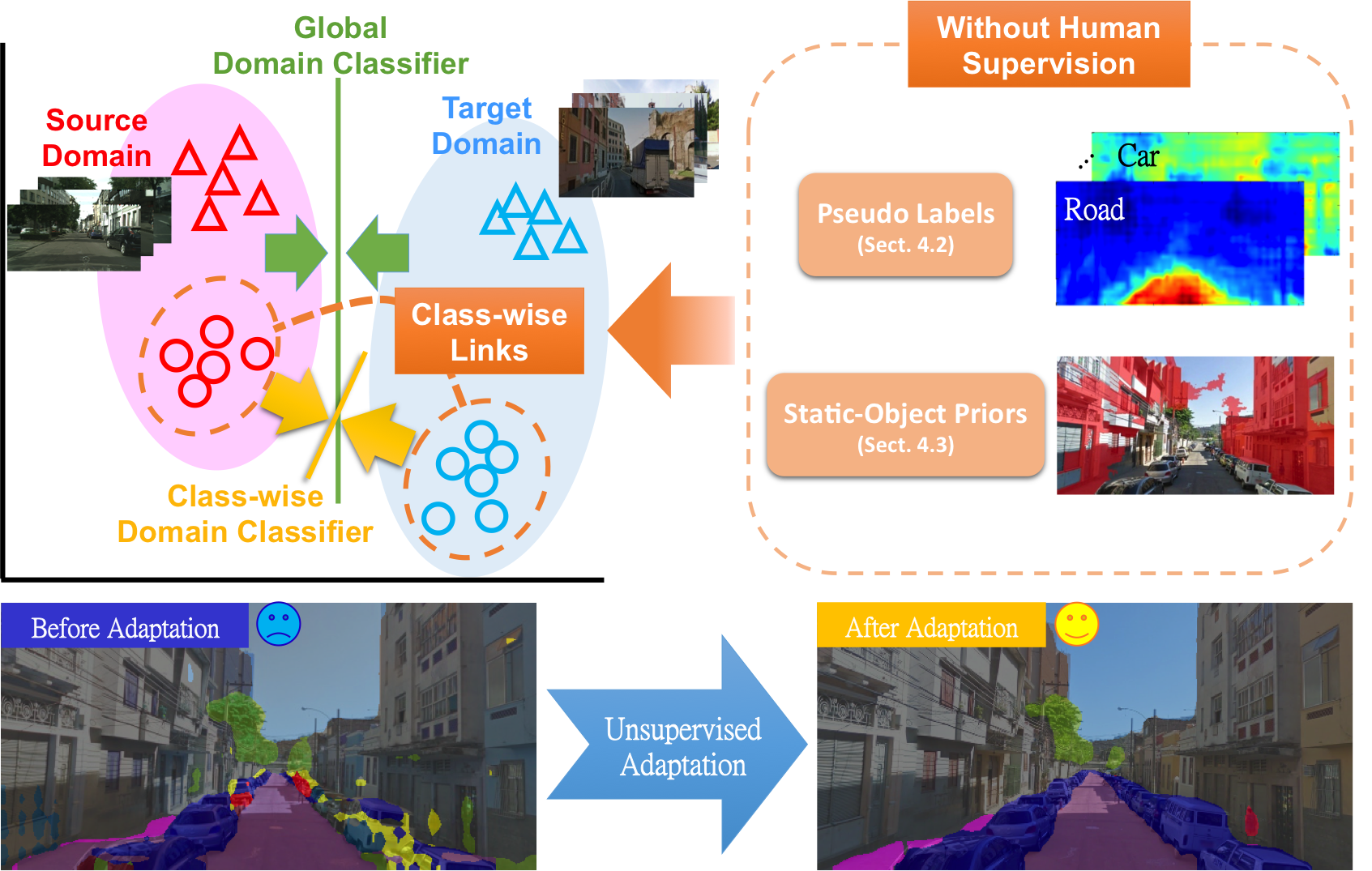
MotivationRecent developments of technologies in computer vision, deep learning, and more broadly artificial intelligence, have led to the race of building advanced driver assistance systems (ADAS). Among those related techniques, road scene segmentation is definitely one of the key components for a successful ADAS. However, even the state-of-the-art semantic segmenter still shows a huge performance panalty when we apply it to an unseen city due to dataset (domain) bias. In the below figures, see how severe a state-of-the-art semantic segmenter, which is pretrained on Cityscapes dataset (cities in Germany, e.g., Frankfurt), will be affected by the dataset bias when we apply it to other unseen cities (Rome, Rio, Tokyo and Taipei).This suggests the urgent necessity of a dataset for the adaptation of road scene segmenter, as well as an effective adaptation method. |
|
|
|
 in the above map to see how poor the segmenter performance is in the unseen city. in the above map to see how poor the segmenter performance is in the unseen city. |
 |




|
















|
|
 |
|


|
|
Download Paper |